做项目(商城项目...),看文档
MySQL查询(MySQL不真正意义上支持全连接)
SELECT - 用于指定要检索的列
FROM - 指定要检索数据的表
WHERE - 可选,用于过滤数据行
ORDER BY - 可选,对结果集排序
LIMIT - 可选,限制返回行数
查询的语法结构:
SELECT 列名
FROM 表名
[WHERE 条件]
[ORDER BY 字段]
[LIMIT 行数]
select ** from exam实际工作中尽量不要使用进行查询,效果
很差,性能很差
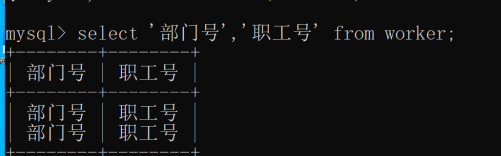
’部门号’,’职工号’:可以是一列,也可以是一个表达式

CREATE TABLE stu (
id int PRIMARY KEY,
name varchar(10),
chinese int,
math int,
english int
);
insert into stu values(1,'夏洛',80,99,59);
别名的语法
select name, chinese+math+english AS '总成绩' from stu; -- 修正表名 stul → stu
SELECT column_name AS alias_name
FROM table_name;
/*
参数说明:
column_name - 要查询的字段名
alias_name - 字段别名
table_name - 要查询的表名
*/
去重DISTINCT:
实例:
select distinct math from exam_result;
| id | name | chinese | math | english |
|---|---|---|---|---|
| 1 | 夏洛 | 80 | 99 | 59 |
| 2 | 潮汐鱼人 | 100 | 59 | 40 |
| 3 | 鱼人 | 120 | 99 | 59 |
CREATE TABLE stu1 (
id INT PRIMARY KEY,
name VARCHAR(10),
chinese INT,
math INT,
english INT
);
INSERT INTO stu1 VALUES
(1, '夏洛', 80, 99, 59),
(2, '潮汐鱼人', 100, 59, 40),
(3, '鱼人', 120, 99, 59);
order by代表的是根据某一列进行排序
select name,math from stul order by math asc;
一般跟desc asc连用,desc 代表降序,asc 代表升序
查询班级学生总成绩,降序排列
select name,(math+chinese+english) as grade from stu1 order by grade desc;
as可以省略
select name , chinese+math+english AS '总成绩', from stul order by 总成绩 desc;
条件的查询
-- 查询数学不及格的学生姓名和成绩
SELECT name, math FROM stu1 WHERE math < 60;
查询语文成绩好于英文成绩的同学
and关键字
select name from stu1 where chinese >80 and math>90;
where 条件1 and 条件2
and 同时条件1 和条件2
where 条件1 or条件2
or是指条件1和条件2至少有一个成立
SELECT * FROM exam_result WHERE chinese > 80 or math >
and english> 70;
AND 和 OR 的优先级:
执行顺序详解:
先执行AND条件:
再执行OR条件:
BETWEEN... AND ... 关键字
-- 查询语文成绩在[80,90]分的同学及语文成绩
SELECT name, chinese
FROM exam_result
WHERE chinese BETWEEN 80 AND 90;
-- 使用AND也可以实现
SELECT name, chinese
FROM exam_result
WHERE chinese >= 80 AND chinese <= 90;
in 的用法:
SELECT column_name FROM table_name WHERE column_name IN (value1, value2, ...);
select name,chinese from stu1 where chinese in(100,20);
模糊查询(like关键字)
MySQL的通配符使用说明:
%匹配任意多个字符_匹配单个字符
尽量不要再开头使用%,会导致该搜索进行全表扫描,造成性能下降。
-- 查询名字以'夏'开头的学生
SELECT name FROM stu1 WHERE name LIKE '夏%';
-- 查询名字包含'鱼'的学生
SELECT name FROM stu1 WHERE name LIKE '%鱼%';
-- 查询名字为3个字且第二个字是'人'的学生
SELECT name FROM stu1 WHERE name LIKE '_人';
limit 是指分页查询
select * from stu1 limit 3; -- 等价于: select * from stu1 limit 0,3;
练习:查询出该表数学成绩大于20,取前三条数据(排名前三的结果)
-- 优化:添加了结果排序
SELECT name, math FROM stu1 WHERE math > 20 ORDER BY math DESC LIMIT 3;
查询语文成绩排名前三的用户
-- 优化:添加了WHERE条件确保有效数据
SELECT name, chinese FROM stu1 WHERE chinese ORDER BY chinese DESC LIMIT 3;
worker表优化
-- 创建worker表(中文字段)
CREATE TABLE `workertest` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 批量插入数据
INSERT INTO `workertest` VALUES
(101, 1001, '2015-05-04', 3500.00, '群众', '张三', '1990-07-01'),
(101, 1002, '2017-02-06', 3200.00, '团员', '李四', '1997-02-08'),
(102, 1003, '2011-01-04', 8500.00, '党员', '王亮', '1983-06-08'),
(102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-09-05'),
(102, 1005, '2014-04-01', 4800.00, '党员', '钱七', '1992-12-30'),
(102, 1006, '2017-05-05', 4500.00, '党员', '孙八', '1996-09-02');
1、显示所有职工的基本信息。
select *from workertest;
2、查询所有职工所属部门的部门号,不显示重复的部门号。
select distinct 部门号 from workertest;
3、求出所有职工的人数。
select count(*) from workertest;
4、列出最高工和最低工资。
select max(工资),min(工资) from workertest;
5、列出职工的平均工资和总工资。
select avg(工资),sum(工资) from workertest;
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
7、显示所有职工的年龄。
8、列出所有姓刘的职工的职工号、姓名和出生日期。
9、列出1960年以前出生的职工的姓名、参加工作日期。
10、列出工资在1000-2000之间的所有职工姓名。
11、列出所有陈姓和李姓的职工姓名。
12、列出所有部门号为2和3的职工号、姓名、党员否。
13、将职工表worker中的职工按出生的先后顺序排序。
14、显示工资最高的前3名职工的职工号和姓名。
15、列出总人数大于4的部门号和总人数。
子查询(嵌套查询):operator
SELECT column1, column2
FROM table_name
WHERE column_name OPERATOR (SELECT column_name FROM table_name WHERE condition);
-- 正确的INSERT结合SELECT语法示例
INSERT INTO stu1 (name)
SELECT name FROM shool WHERE age=18 AND id=5;
有一张员工表,员工表里面,有每个人的名字有一个工资表。有每个员工的工资
select name from employees where salary > (select avg(salary) from salary)
聚合函数:
聚合函数:
COUNT() - 用于计算行数
语法: SELECT COUNT(column_name) FROM table_name;
示例: SELECT COUNT(*) FROM employees;
SUM() - 用于计算数值列总和
语法: SELECT SUM(column_name) FROM table_name;
示例: SELECT SUM(salary) FROM employees;
聚合函数:
1. AVG() - 计算数值列的平均值
语法: SELECT AVG(column_name) FROM table_name;
示例: SELECT AVG(salary) FROM employees;
2. MAX() - 返回列中的最大值
语法: SELECT MAX(column_name) FROM table_name;
示例: SELECT MAX(salary) FROM employees;
3. MIN() - 返回列中的最小值
语法: SELECT MIN(column_name) FROM table_name;
示例: SELECT MIN(salary) FROM employees;
avg 子查询
-- 正确的写法:使用子查询先计算平均工资
SELECT COUNT(*) FROM workertest WHERE 工资 > (SELECT AVG(工资) FROM workertest);
group by 分组查询
数据分组:按一列或多列的值将数据划分为逻辑组。
聚合计算:对每个分组应用聚合函数(如COUNT、SUM、AVG、
MAX、MIN)进行统计。
结果过滤:通过HAVING对分组后的结果进行筛选(区别于WHERE的
分组前过滤
-- 基本语法
SELECT 列名, 聚合函数(列名)
FROM 表名
[WHERE 条件]
GROUP BY 列名
[HAVING 分组条件];
-- 实际示例
SELECT 部门号, AVG(工资) as 平均工资
FROM workertest
GROUP BY 部门号
HAVING AVG(工资) > 4000;
单列分组统计:统计每个部门的员工数量和平均工资。
SELECT
部门号 AS department,
COUNT(*) AS emp_count,
AVG(工资) AS avg_salary
FROM workertest
GROUP BY 部门号;
select 政治面貌,avg(工资) as avg_salary from workertest group by 政治面貌;
按部门和职位统计员工数量。
-- 修正为使用中文字段名并添加注释说明
SELECT
部门号 AS department,
政治面貌 AS job_title,
COUNT(*) AS emp_count
FROM workertest
GROUP BY 部门号, 政治面貌;
/*
说明:按部门和职位统计员工数
*/
同时进行分组查询
select 部门号,政治面貌,count(*) from workertest group by 政治面貌,部门号;
select 部门号,政治面貌,count(*) from workertest group by 部门号,政治面貌;
修复:1. 交换了下分组顺序(先按部门号分组更合理)2. 改为count(*)更标准 3. 补全了结尾分号
group by 跟 having进行联用
HAVING是SQL中用于对分组后的结果进行筛选的关键字。
它通常与GROUP BY配合使用,用于过滤聚合函数(如
COUNT、SUM、AVG等)的结果。
-- 筛选员工数量超过5人的部门示例
SELECT 部门号, COUNT(*) AS 员工数
FROM workertest
GROUP BY 部门号
HAVING COUNT(*) > 5;
对分组之后的结果再一次做筛选
select 部门号,政治面貌,count(*) from workertest group by 部门号,政治面貌 having count(*) < 2;
多表查询
select name,姓名 from stu1,workertest;(错误的演示)
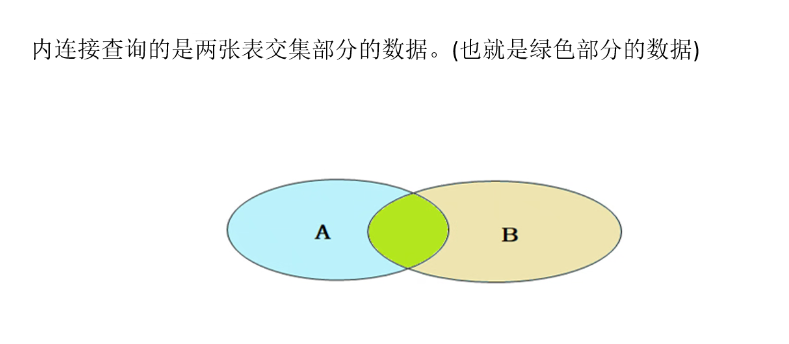
内连接:内连接(INNER JOIN)是MySQL中最常用的连接类型
之一,它仅返回两个表中满足连接条件的匹配记录。当您需
要从多个相关联的表中获取数据时,内连接提供了一种高效
的方式。
隐式内连接:
SELECT 字段列表 FROM 表1, 表2 WHERE 条件;
显示内连接:
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件;
-- 优化为更规范的显示内连接语法
SELECT emp.name, dept.name
FROM emp INNER JOIN dept
ON emp.dept_id = dept.id;
-- 修正了格式和引号问题
insert into emp values(1,1,'张飞'),(2,2,'貂蝉'),(3,3,'勾践'),(4,2,'黄月英');
隐式内连接
select name, dept_name from emp, dept where emp. dept_id=dept. dept_id;
显式内连接(select name, dept_name from emp e join dept d on e.dept_id=d. dept_id;)
SELECT name,dept_name FROM emp INNER JOIN dept ON emp.dept_id = dept.dept_id;
三表的联查
-- 修正错误的连接条件和格式
select name, dept_name, salary
from emp e
join dept d on e.dept_id = d.dept_id
join sal s on e.id = s.emp_id
-- 创建工资表
CREATE TABLE sal (
id INT PRIMARY KEY AUTO_INCREMENT,
emp_id INT NOT NULL,
salary DECIMAL(10,2) NOT NULL,
effective_date DATE NOT NULL
);
-- 插入示例数据
INSERT INTO sal (emp_id, salary, effective_date) VALUES
(1,1, 8000.00, '2024-01-01'),
(2,2, 7500.00, '2024-01-01'),
(3,3, 9000.00, '2024-01-01'),
(4,4, 8200.00, '2024-01-01);
select *from sal
+----+--------+---------+----------------+
| id | emp_id | salary | effective_date |
+----+--------+---------+----------------+
| 1 | 1 | 8000.00 | 2024-01-01 |
| 2 | 2 | 7500.00 | 2024-01-01 |
| 3 | 3 | 9000.00 | 2024-01-01 |
| 4 | 4 | 8200.00 | 2024-01-01 |
+----+--------+---------+----------------+
4 rows in set (0.00 sec)
mysql> select *from dept
-> ;
+---------+-----------+
| dept_id | dept_name |
+---------+-----------+
| 2 | 江东jerry |
| 3 | 大魏国 |
| 1 | 蜀国 |
+---------+-----------+
3 rows in set (0.00 sec)
mysql> select *from emp;
+--------+---------+--------+
| emp_id | dept_id | name |
+--------+---------+--------+
| 1 | 1 | 张飞 |
| 2 | 2 | 貂蝉 |
| 3 | 3 | 勾践 |
| 4 | 2 | 黄月英 |
+--------+---------+--------+
4 rows in set (0.00 sec)
员工表 部门表 工资表 查询出测试部门所有大于平均工资的员工(sql):
-- 查询测试部门工资高于平均工资的员工(修正了表连接条件)
SELECT emp.name, sal.salary
FROM emp
JOIN dept ON emp.dept_id = dept.dept_id
JOIN sal ON emp.emp_id = sal.emp_id
WHERE sal.salary > (SELECT AVG(salary) FROM sal);
左外连接(以左表为主连接,查右表内容)右外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON
条件….;
案例:
A. 查询emp表的所有数据,和对应的部门信息
由于需求中提到,要查询emp的所有数据,因为有一条数据没有
dept_id,所以是不能内连接查询的,需要考虑使用外连接查询。
select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
查询dept表的所有数据,和对应的员工信息(右外连接,查左表内容)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询
的,需要考虑使用外连接查询。
表结构:emp, dept
连接条件: emp.dept_id = dept.id
内连接,只是查出表相交集的数据
select d.,e. from emp e right outer join dept d on d.id = e.dept_id;
select d.,e. from dept d left outer join emp e on d.id= e.dept_id;
1.创建student和score表
CREATE TABLE student1 (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
2.为student1表和score表增加记录
向student表插入记录的INSERT语句如下:
INSERT INTO student1 VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student1 VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student1 VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student1 VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student1 VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student1 VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);
3.查询student表的所有记录
4.查询student表的第2条到4条记录
5.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
6.从student表中查询计算机系和英语系的学生的信息
7.从student表中查询年龄18~22岁的学生信息
8.从student表中查询每个院系有多少人
9.从score表中查询每个科目的最高分
10.查询李四的考试科目(c_name)和考试成绩(grade)
11.用连接的方式查询所有学生的信息和考试信息
12.计算每个学生的总成绩
13.计算每个考试科目的平均成绩
14.查询计算机成绩低于95的学生信息
15.将计算机考试成绩按从高到低进行排序
ifconfig
查询18-22岁的学生信息
-- 修正:添加了查询条件列并调整了语法格式
SELECT * FROM student1
WHERE (YEAR(CURDATE()) - birth) BETWEEN 18 AND 22;
-- 查询计算机成绩低于95的学生信息(使用内连接)
SELECT s.*
FROM student1 s
INNER JOIN score sc ON s.id = sc.stu_id
WHERE sc.c_name = '计算机' AND sc.grade < 95;